SpaceTimeGPT
Video Captioning with TimeSformer + GPT-2 via DeepSpeed Pipeline Parallelism
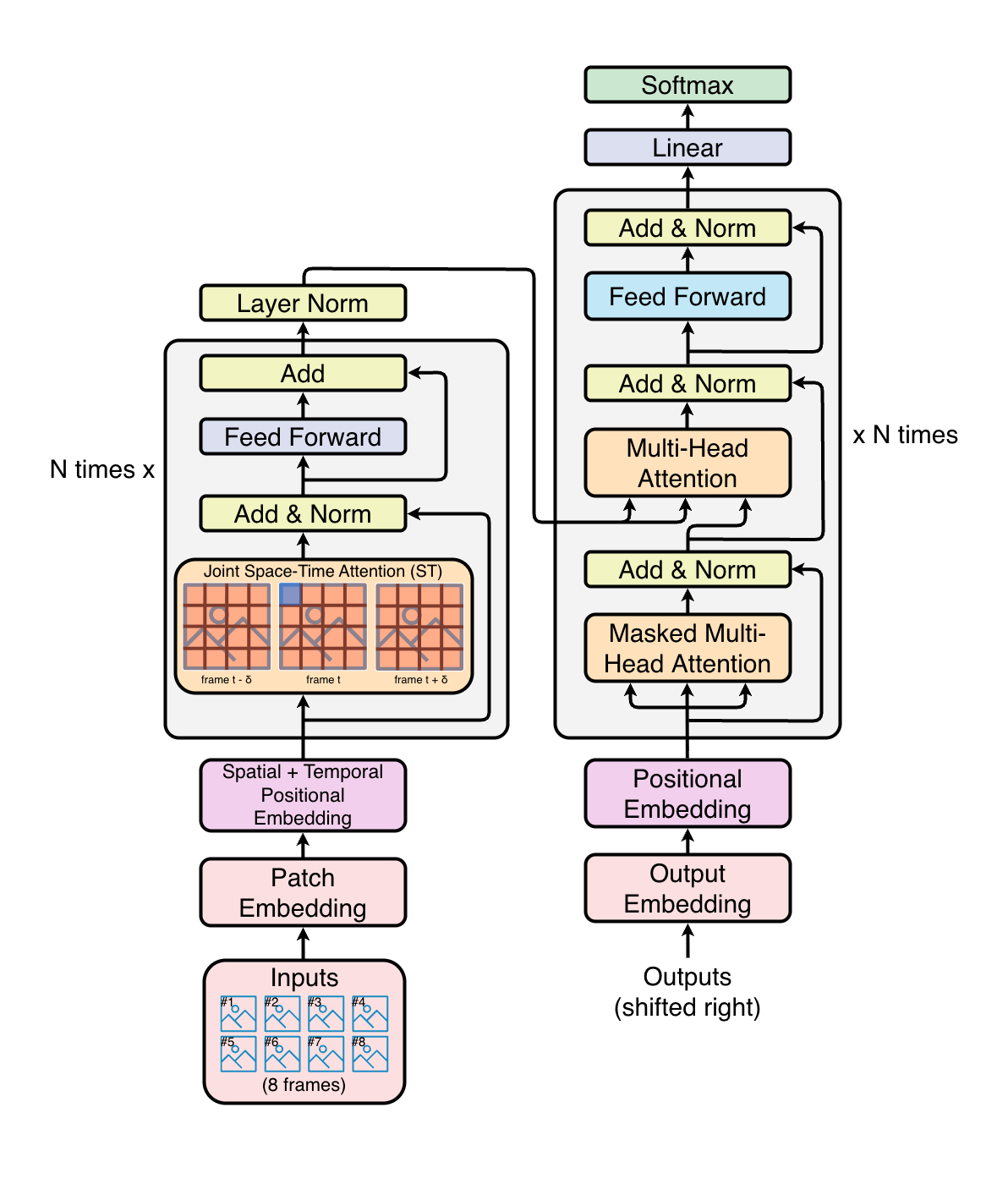
Overview
TimesGPT is a distributed video captioning system that pairs a TimeSformer vision encoder with a GPT-2 language decoder inside a unified encoder-decoder framework. The model ingests short video clips (represented as sequences of frames), extracts rich spatiotemporal features, and autoregressively generates natural-language captions describing the visual content.
To train and evaluate models at scale, the entire encoder-decoder stack is split across multiple GPUs using DeepSpeed’s Pipeline Parallelism, allowing configurations that would not fit in a single GPU’s memory to be trained efficiently across multi-node HPC clusters.
The code is in progress to make publically available.
Team & Contributions
| Name | Role |
|---|---|
| Juvenal Francisco Barajas | Machine Learning Researcher & Lead Developer – model architecture, DeepSpeed pipeline integration, training infrastructure |
| Andrew T. Scott | Principal Investigator (PI) & Lead Developer – architecture, codebase, technical implementation |
| Gio Jung | Data Analyst & Collaborator – distributed deployment, scaling experiments, HPC integration, analytical support |
| Dr. Ilmi Yoon | Co-Principal Investigator (Co-PI) – advisory role |
(Note: The primary contributors to the codebase and technical work were Juvenal Barajas and Andrew Scott. Gio Jung and Dr. Ilmi Yoon provided support in analytical and advisory roles.)
Background: From Single-GPU to HPC with NAIRR
This project was originally developed and trained on the university’s local GPU server equipped with a single NVIDIA A6000 (48 GB VRAM). While sufficient for prototyping and small-scale experiments, the A6000 imposed hard limits on model size, batch size, and training throughput.
In Fall 2024, our team was awarded a compute allocation through the National Artificial Intelligence Research Resource (NAIRR) Pilot program. NAIRR is an NSF-led initiative that provides researchers and students access to high-performance computing infrastructure that would otherwise be unavailable to them. Through this allocation, we were granted access to NVIDIA H100 GPU nodes at the Pittsburgh Supercomputing Center (PSC).
This HPC access fundamentally changed what was possible:
- Pipeline parallelism – Splitting the encoder-decoder model across multiple GPUs became practical, enabling us to experiment with deeper architectures and larger hidden dimensions.
- Multi-node training – SLURM-managed job scheduling and
torchrunelastic launch allowed training to scale across nodes seamlessly. - Faster iteration – What previously took days on a single A6000 could now run in hours across multiple A100s and H100s.
The codebase supports both environments: sbatch_scripts/ref_run_h100_2nodes_16gpus_100p.sh targets SLURM-managed HPC clusters (using srun for multi-node orchestration), while sbatch_scripts/testrun.sh is designed for our local multi-GPU server where torchrun alone handles distribution without SLURM. Both scripts use the same DeepSpeed pipeline parallelism under the hood.
Tech Stack
| Layer | Technology |
|---|---|
| Deep Learning Framework | PyTorch |
| Model Components | HuggingFace Transformers (VisionEncoderDecoderModel, TimesformerModel, GPT2LMHeadModel) |
| Distributed Training | DeepSpeed (Pipeline Parallelism, ZeRO Stage 1) |
| Distributed Launch | torchrun (PyTorch Elastic) |
| Experiment Tracking | Weights & Biases (W&B) |
| Evaluation Metrics | pycocoevalcap (BLEU, METEOR, ROUGE, CIDEr, CIDEr-D, SPICE) |
| Dataset Format | Pre-processed .npz archives (pixel tensors + tokenized captions) |
| Precision | FP16 mixed-precision training |
| HPC Orchestration | SLURM (sbatch / srun) on PSC H100 nodes; torchrun standalone on local server |
Model Architecture
The model follows a transformer-based encoder-decoder design, bridging video understanding and language generation.
Encoder: TimeSformer
TimeSformer (Time-Space Transformer) is a Vision Transformer adapted for video. Instead of processing a single image, it operates over a sequence of sampled video frames (default: 8 frames of 224x224 pixels).
Key characteristics of the encoder:
- Patch Embedding – Each frame is split into non-overlapping 16x16 patches. The patches from all frames are flattened into a single sequence of tokens, prepended with a learnable
[CLS]token and augmented with positional embeddings. - Joint Space-Time Attention – The core innovation of TimeSformer. Rather than applying full self-attention over all patches across all frames (which is quadratically expensive), each transformer block applies temporal attention (across frames at the same spatial location) and spatial attention (across patches within the same frame) in two separate steps. This factorization drastically reduces compute while still capturing motion and appearance.
- Configurable Depth – The number of transformer layers, hidden size, attention heads, and intermediate size are all parameterized (defaults: 12 layers, 768 hidden dim, 12 heads), allowing scaling experiments.
- Pretrained Backbone – Initialized from
facebook/timesformer-base-finetuned-k600, a TimeSformer pretrained on the Kinetics-600 action recognition dataset.
The encoder produces a sequence of hidden states (one per patch-token across all frames) that serve as the visual context for the decoder.
Decoder: GPT-2
GPT-2 is used as the autoregressive language model that generates captions token-by-token. The standard GPT-2 architecture is extended with cross-attention layers so that each decoder block can attend to the encoder’s visual output.
Key characteristics of the decoder:
- Cross-Attention – Every GPT-2 transformer block contains an additional cross-attention sub-layer that attends over the encoder hidden states. This is the mechanism through which the language model “sees” the video content.
- Causal (Left-to-Right) Self-Attention – The standard GPT-2 masked self-attention ensures the model generates tokens autoregressively, where each new token can only attend to previously generated tokens.
- Teacher Forcing – During training, ground-truth caption tokens are shift-right prepended with a BOS token and fed to the decoder. The model is trained with cross-entropy loss against the original labels.
- Configurable Depth – Like the encoder, the decoder’s layer count, embedding dimension, number of heads, and context length are all parameterized (defaults: 12 layers, 768 hidden dim, 12 heads, 1024 context length).
- Pretrained Backbone – Initialized from
openai-community/gpt2and supports scaling to GPT-2 Medium or GPT-2 XL.
Encoder-Decoder Bridge
HuggingFace’s VisionEncoderDecoderModel provides the glue between TimeSformer and GPT-2. It handles:
- Passing encoder hidden states to the decoder’s cross-attention layers.
- The shift-right mechanism that prepends a BOS token to decoder inputs during training.
- Tied word embeddings between the decoder’s input embedding layer and the output LM head (reducing parameter count and improving training stability).
Pipeline Parallelism with DeepSpeed
The defining engineering challenge of this project is distributing a large encoder-decoder model across multiple GPUs using DeepSpeed’s Pipeline Parallelism. Unlike data parallelism (where each GPU holds a full copy of the model), pipeline parallelism partitions the model’s layers across GPUs, forming a pipeline where each GPU is responsible for a subset of the computation.
Why Pipeline Parallelism?
On a single A6000, the model size was capped by 48 GB of VRAM. With pipeline parallelism on the NAIRR-allocated H100 nodes, each GPU only needs to hold a fraction of the model, unlocking significantly larger configurations:
- Memory efficiency – Each GPU only holds a fraction of the model’s parameters. This enables training much larger models (deeper encoders/decoders, higher hidden dimensions) than any single GPU could accommodate.
- Scalability – The pipeline can span multiple GPUs across multiple nodes. The project has been tested with configurations up to 16 GPUs across 2 nodes of H100s on PSC.
- Complementary to ZeRO – Pipeline parallelism is combined with DeepSpeed ZeRO Stage 1 (optimizer state partitioning) for additional memory savings.
How the Model is Split into Pipeline Stages
DeepSpeed’s PipelineModule requires the model to be expressed as a flat sequence of layers (not a nested module tree). This project manually decomposes the HuggingFace VisionEncoderDecoderModel into pipeline-compatible wrapper layers:
Stage 0 (GPU 0) Stage 1 (GPU 1) Stage 2 (GPU 2)
┌───────────────────┐ ┌───────────────────┐ ┌───────────────────┐
│ EncEmbedWrapper │ │ EncBlockWrapper │ │ DecBlockWrapper │
│ (patch embed + │ │ (encoder layers │ │ (decoder layers │
│ pos embed) │ │ continued) │ │ continued) │
│ │────▶│ │────▶│ │
│ EncBlockWrapper │ │EncLayerNormWrapper│ │ FinalWrapper │
│ (encoder layers) │ │ │ │ (LayerNorm + │
│ │ │ DecTokenEmbedWrap │ │ LM Head) │
│ │ │ (token + pos emb)│ │ │
│ │ │ │ │ │
│ │ │ DecBlockWrapper │ │ │
│ │ │ (decoder layers) │ │ │
└───────────────────┘ └───────────────────┘ └───────────────────┘
▲ │
│ Micro-batch pipeline │
└──────────────────────────────────────────────────┘
Each wrapper layer carries three values through the pipeline as a tuple: (encoder_hidden_states, decoder_input_or_labels, metadata_tensor). This tuple protocol is critical because DeepSpeed’s pipeline engine only passes a single tensor (or tuple of tensors) between stages – there is no concept of keyword arguments or named outputs.
The pipeline wrappers include:
| Wrapper | Role |
|---|---|
EncEmbedWrapper | Patch + positional + CLS embedding for video frames |
EncBlockWrapper | Single TimeSformer transformer layer |
EncLayerNormWrapper | Final LayerNorm on encoder output |
DecTokenEmbedWrapper | Token + position embeddings for decoder, plus attention mask construction. Handles both teacher-forcing (training) and autoregressive (generation) modes. |
DecBlockWrapper | Single GPT-2 transformer block with self-attention and cross-attention |
FinalWrapper | Final LayerNorm + linear LM head that projects to vocabulary logits |
Tied Weights Across Pipeline Stages
The decoder’s input embedding matrix and the output LM head share the same weights (weight tying). Since these layers may land on different pipeline stages (different GPUs), DeepSpeed’s TiedLayerSpec is used to declare shared parameters. DeepSpeed handles the gradient synchronization for tied weights across stages automatically.
Partition Strategy
DeepSpeed offers multiple methods for deciding which layers go to which GPU:
-
**parameters**(default) – Balances by total parameter count per stage, placing heavier layers together. -
**uniform**– Distributes layers evenly by count. -
**type:transformers**– Groups by module type.
The parameters method is the default, as it tends to balance memory consumption most effectively when encoder and decoder blocks have different parameter counts.
Training Pipeline
Dataset
The model is trained and evaluated on the VATEX (Video-and-Text) dataset, which contains diverse video clips paired with multiple English captions per video (10 captions used per video in training). Video frames are pre-extracted and stored as preprocessed tensors in .npz format for efficient I/O during distributed training.
Data Preprocessing
Video frames and captions are pre-processed offline into .npz archives. Each archive contains:
-
arr_0: A tensor of shape(num_frames, 3, H, W)– the preprocessed video frames. -
arr_1: A matrix of shape(num_captions, context_length)– tokenized caption variants for the same video (up to 10 captions per video from the VATEX dataset).
This pre-processing step avoids expensive video decoding and tokenization during training.
Training Loop
Training uses DeepSpeed’s PipelineEngine.train_batch(), which orchestrates micro-batch scheduling across pipeline stages:
- The data loader emits
((pixel_values, labels, metadata), labels)tuples. - DeepSpeed splits each batch into micro-batches and pipelines them across GPUs.
- Forward and backward passes for different micro-batches overlap across stages (pipeline interleaving), maximizing GPU utilization.
- Gradients are accumulated over configurable steps before an optimizer update.
- A linear learning rate scheduler with warmup is applied.
Checkpoints are saved at every epoch and support both standard and universal checkpoint formats. Universal checkpoints allow resuming training on a different number of GPUs than originally used (e.g., training on 16 GPUs, then resuming on 8) – particularly useful when transitioning between the local server and NAIRR HPC resources.
Decoding Strategies
At inference time, captions are generated autoregressively. Because the model is distributed across pipeline stages, decoding requires coordination:
- Greedy Decoding – At each step, the full pipeline runs a forward pass. Only the last pipeline stage (which holds the LM head) has access to logits. It selects the argmax token and broadcasts it to all other stages via
dist.broadcast(). This repeats until an EOS token is produced or the maximum length is reached. - Top-k / Top-p (Nucleus) Sampling – Similar to greedy, but the last stage applies temperature scaling, top-k filtering, and nucleus (top-p) truncation before sampling from the resulting distribution. The sampled token is then broadcast to all stages.
Both strategies handle early stopping when all sequences in the batch have produced an EOS token.
Evaluation Metrics
Generated captions are evaluated against multiple ground-truth references (up to 10 per video) using standard captioning metrics:
| Metric | What It Measures |
|---|---|
| BLEU-1/2/3/4 | N-gram precision (unigram through 4-gram overlap) |
| METEOR | Unigram alignment with stemming, synonymy, and recall weighting |
| ROUGE-L | Longest common subsequence between prediction and reference |
| CIDEr | TF-IDF weighted n-gram similarity, designed specifically for captioning |
| CIDEr-D | CIDEr variant with length penalty and stemming |
| SPICE | Semantic propositional content via scene graph parsing |
All metrics are computed using the pycocoevalcap library (from the MS COCO evaluation toolkit) and logged to W&B at the end of each epoch.
Experiment Tracking with Weights & Biases
All training runs are tracked using Weights & Biases (W&B), providing real-time visibility into training dynamics and model performance.
What Is Logged
- Training loss – Per-batch and per-epoch average loss.
- Validation loss – Per-batch and per-epoch average loss.
- Learning rate – Current learning rate at each training step (useful for diagnosing scheduler behavior).
- Captioning metrics – BLEU, METEOR, ROUGE, CIDEr, CIDEr-D, and SPICE scores after each evaluation epoch.
- Hyperparameters – Full configuration snapshot including encoder/decoder depth, hidden sizes, number of frames, batch size, world size, precision settings, and more.
W&B Configuration
Only the last pipeline stage (which computes the loss and generates captions) initializes and logs to W&B. This avoids duplicate logging from other pipeline stages.
Each experiment run is uniquely identified by a structured name encoding all key hyperparameters (e.g., VATEX-psc-H100-run_ws16_nc10_ss1.0_enl12_dnl12_dhs768_ehs768_nf8_ps16_lr5e-07_bs16_rs42), making it easy to compare runs in the W&B dashboard.
Custom metric axes are defined so that loss and captioning metrics can be plotted against the epoch number rather than the global step.
Qualitative Results
After evaluation, the system generates an HTML report containing side-by-side comparisons of:
- The original video frames (un-normalized and rendered as inline images).
- The model’s predicted caption.
- All ground-truth reference captions.


Deployment Environments
The codebase is designed to run seamlessly in two different hardware environments:
SLURM-Managed HPC (PSC H100 Nodes via NAIRR)
Used for full-scale training runs. SLURM sbatch scripts handle:
- Multi-node orchestration via
srun+torchrun. - Automatic master address/port discovery from SLURM environment variables (
SLURM_NODELIST,SLURM_JOB_ID). - Configurable GPU count per node and number of nodes.
Local Multi-GPU Server (No SLURM)
Used for development, debugging, and smaller-scale experiments. The testrun.sh script launches torchrun directly (without srun or sbatch), targeting specific GPUs via CUDA_VISIBLE_DEVICES. Pipeline parallelism still runs across multiple local GPUs – the DeepSpeed code is identical in both environments.
Example configurations tested:
- 1 GPU (A6000), 1 node – Original single-GPU development environment (without parallelism).
- 3 GPUs, 1 node – Local multi-GPU server for pipeline parallelism development and testing.
- 16 GPUs (8 per node), 2 nodes of NVIDIA H100s – Full-scale training on PSC via NAIRR.
References
- Bertasius, G., Wang, H., & Torresani, L. (2021). Is Space-Time Attention All You Need for Video Understanding? Proceedings of the International Conference on Machine Learning (ICML). arXiv:2102.05095
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners. OpenAI Technical Report. PDF
- Rasley, J., Rajbhandari, S., Ruwase, O., & He, Y. (2020). DeepSpeed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. deepspeed.ai
- Wang, X., Wu, J., Chen, J., Li, L., Wang, Y., & Wang, W. Y. (2019). VaTeX: A Large-Scale, High-Quality Multilingual Dataset for Video-and-Language Research. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). vatex.org
- Vedantam, R., Zitnick, C. L., & Parikh, D. (2015). CIDEr: Consensus-based Image Description Evaluation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- NSF National Artificial Intelligence Research Resource (NAIRR) Pilot. nairrpilot.org